Fast 3D & Depth-separable Convolution on HiFi4 DSP
With the rise of several machine learning and deep learning algorithms, the need for robust and efficient hardware is widely known. Specific to Automatic Speech Recongnition (ASR), conventional Digital Signal Processors (DSPs) do not accommodate the needs of fast and hefty computational requirements of deep learning algorithms. This motivates the design of newer designs of DSPs customizable to deep learning algorithms.
Cadence pioneers in the design of DSPs for audio and voice algorithms. HiFi 4 is one such design by engineers and scientists at Cadence which enables efficient computing coupled with low memory footprint. HiFi 4 DSP is a highly optimized audio and voice processor built for efficient execution of audio and voice codecs and pre- and post-processing modules along with other demanding DSP functions in areas such as ASR, wireless communications.
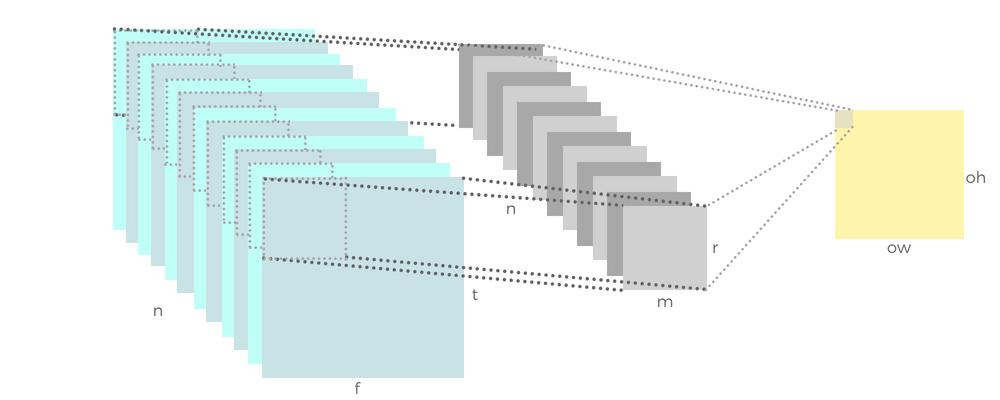
In summers of 2018, I worked on devising efficient algorithms to implement 3D and Depth Separable Convolution on HiFI 4. Leveraging the parallel design of HiFi 4 coupled with assembly-level MAC (multiply and accumulate) operations, I was able to speed up the CNN implementation by 4000% as compared to a high-level optimized implementation 1. This enables real-time processing in ASR applications.
Along with the conventional gradient-based optimization method used in machine learning, some applications require using discrete-optimization methods. Foreseeing the need to fasten such integer-based optimization algorithms, I implemented a customizable framework of fixed-point implementation of convolution along with the conventionally used floating-point counterpart. The performance as well as memory footprint in fixed-point implementation was 60-80x better than that of high-level implementation 2.
Additionally, I designed customizable modules of 3D convolution (similar to what Tensorflow or Keras has to offer for CPUs and GPUs) which would be packaged with the DSP for commercial usage by clients. This enabled the users of HiFi 4 worldwide to run deep learning algorithms efficiently for several voice-based applications without having to know the complex details of the hardware specifications and features of HiFi 4.