Plasticity-based Learning in DNNs

Plasticity is essential component in many biological neural networks, however many state of the art deep learning methods do not incorporate plasticity. Taking inspiration from the main mechanism of learning in biological brains: synaptic plasticity, carefully tuned by evolution to produce efficient lifelong learning, me along with my friend Uddeshya explored how could plasticity be infused in Deep and Convolutional Neural Networks to enhance the performance in terms of accuracy and memory footprint. We proposed a methodology on how to train such networks and study the effect of plasticity in different settings.
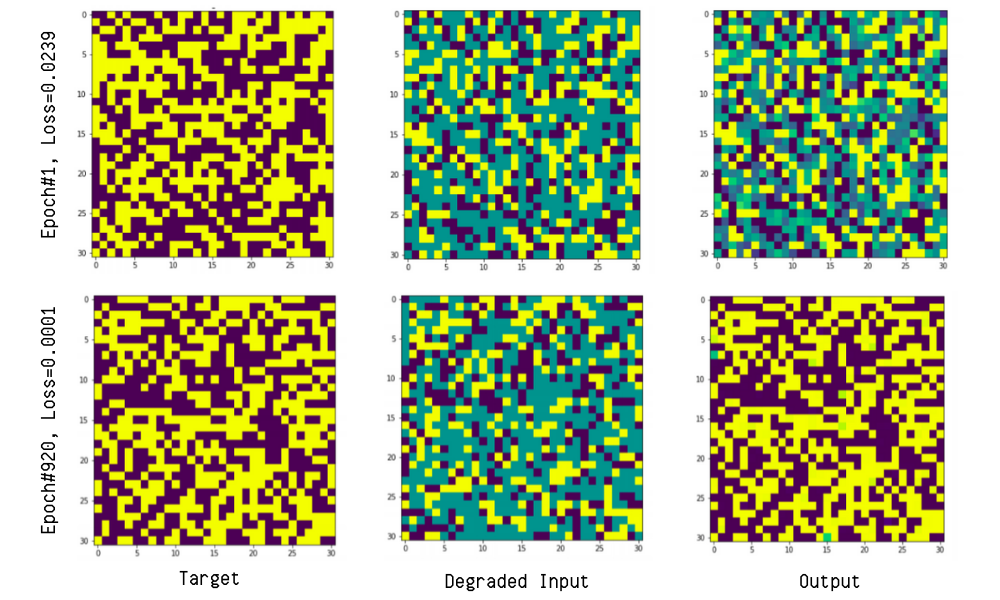
In the task of pattern reconstruction, we used Hebbian plasticity rule to start with. We first consider the problem of reconstructing the
given input to a desired output with minimum loss. Herein, each input is a vector of values in
, of size in_dim. This input vector is degraded by randomly changing
some s and s to 0. Now, this degraded vector is passed as an input to a fully-connected layer of neurons, each of which following the hebbian plasticity rule. We were able to recontruct of the input structure in ~900 epochs of training.
The results of this simple reconstruction task were encouraging, so we extended the analysis to public datasets like MNIST and FMNIST. To this end, we used an encoder-decoder based network with an additional fully-connected layer after encoder as well as decoder. Here too, the performance was better than that of non-plastic network. We were able to observe that our model performs significantly better for tasks of denoising. The future implications of this could be that we could include a plasticity-infused layer for denoising of corrupted data and subsequently deploy classification techniques, improving overall accuracy with a simpler model.

The inclusion of Plasticity in conventional neural network architecture promises good results in certain experiments. However, when we tried including plasticity in more common set of vision related task (denoising, classification), we failed to find much improvement over the baseline model not using plasticity. One of the drawback of using this framework of plasticity is that it fails to perform well when inputs are passed in batches and hence requires the input to be provided as one sample at a time, this inherently makes the training much slower even on GPUs since we can’t process multiple samples at a time.